If you’ve looked at your account dashboard recently, you might have seen a list that looks something like this:
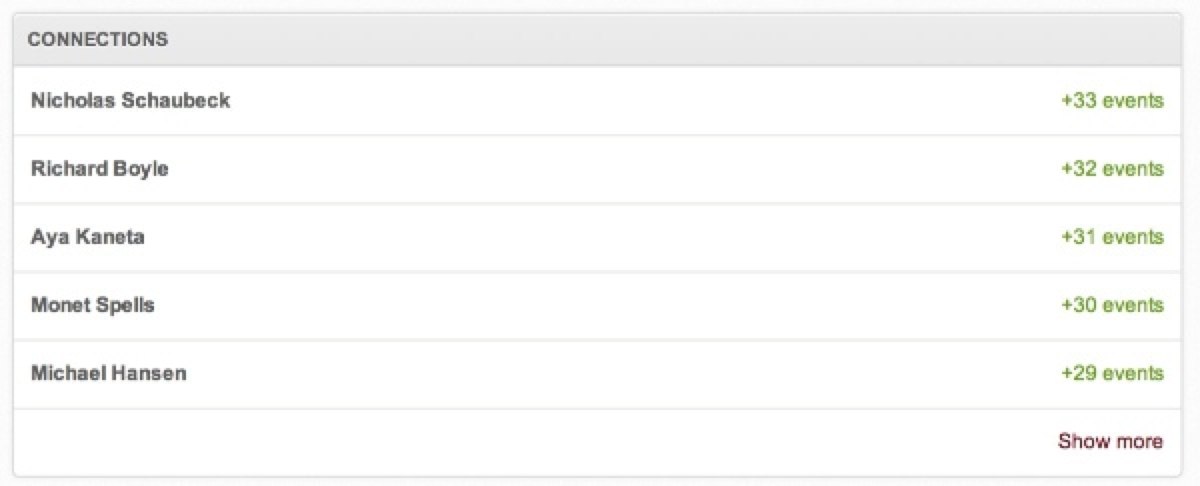
This is a list of everyone you’ve attended events with and how many times you’ve done so. What follows is a story of how we made this possible, and some of the decisions and changes we made along the way. The feature begins from a desire to give users new ways to use their accounts, and to expose the network that already existed between our users.
The first part of the process was to shift the way we think about our accounts. Previously, someone had an “account” when they registered for the site. The reality, however, is that most users on the site are already some kind of account, whether they are logged in to create and send a card or viewing as a guest. Even if someone has never registered on the site they have a history: past events, an email address, probably a name given by a host, and connections to other people. We realized it would be helpful to have a single unique identifier for each of these users, regardless of their state. Since we would have to make an account when someone registered anyway, we decided to expand our definition of account to have an idea of registered vs. unregistered.
When we started, we had a little over 40 million account-like items we wanted to turn into accounts, about ~7% of which were already registered accounts. What weren’t already accounts were mainly email addresses tied to people’s address books or guests on events. We added a registered flag to our accounts, and inserted the 40 million accounts in about 19 hours (that’s about 585 accounts per second). The speed of this script was greatly helped by SQL’s batch inserts, allowing us to get a group of account ids that we then associated to rows in other tables.
Once we had all the accounts associated with email addresses and guests, we could focus on how we were going to combine all the data. We discussed three main ideas for how to go about doing this: a separate application, a table in our main database, and a separate database in our main application. Whatever we decided upon would be responsible for serving links between accounts, keeping the links up to date, and being autonomous of our main application. In terms of autonomy, we wanted our main application’s availability to be unaffected by the status of this new service. In other words, if the links database goes down or we decide to bring it down, we should be able to do that without affecting the rest of our applications.
Option 1: Separate application
We love Go, and discussed the idea of writing an application dedicated to these responsibilites to live in our universe. The advantages of this approach are particularly in the autonomy. Because everything would be served over HTTP, a failed request would be easy to catch and handle, and all the application’s resources would be separated from our main application. However, the HTTP requirement would have been a restriction in both speed and how much data we could feasibly pass at once. Given the tone of this paragraph and the title of this post, you have probably already guessed that we did not choose this option.
Option 2: Same application, same database
This is kind of the “easy option.” From a development perspective, adding some classes and a new table is an easy task, and having it all in the same application makes things as fast as the code you write. However, we expected this table to be very large initially, and grow very quickly (about 80 million new links per month). The fact that this would live in our database paired with the total loss of autonomy made this option undesirable.
Option 3: Same application, different database
This option ended up being sort of the best of the first 2. Rails makes it very easy to have a second database connected to the application, and have models that live in that database. Performance-wise, we are able to communicate with a local SQL database and leverage SQL’s aggregation strengths to make queries fast. Furthermore, the way we set it up, we can disable the link service without affecting the availability of our main application. Having an Active Record model also gives us the convenience of being able to use all the rails model methods, without having to re-write functionality like named scopes.
We have one main table for the links, which stores two accounts, an event and the type of link. In terms of the types of links, we store different relationships; attending an event with someone is different than attending an event with the person that invited you. In the future we will keep track of more link types as well, allowing people to see and use their data in even more ways, potentially being able to make lists and track their connections.
Links are indexed every hour by a cron job that picks up the last hour of events and links all the accounts accordingly. Again, this technique utilizes the infrastructure we already had in place, rather than requiring us to expand or create new things.
To backfill the four years worth of links, we essentially ran a few long running instances of the cron job, and disabled the normal schedule until everything was filled. In one week, we inserted about 169 million link rows. At that point, we enabled the cron job and things began indexing normally.
Once this was all done, it became easy to quickly produce the list above (it’s just one SQL query with a count of events and a group by account id). In just about a month, we were able to change some fundamental ways we view things in our application and introduce a new service, all with techniques and technologies that already existed in our application universe. SQL is immensely powerful, even when faced with hundreds of millions of entries (at time of writing we have close to 190 million links), and leveraging both its strengths and the strengths of Rails, we were able to produce an elegant, fairly simple solution that is accessible to the whole development team and as easy to maintain as the rest of our code.